
High Performance Complex Event Processing
Complex Event Processing
Complex Event Processing (CEP):: consists of processing many events happening across all the layers of an organization, identifying the most meaningful events within the event cloud, analyzing their impact, and taking subsequent action in real time.1
- Example Applications:
- Airbag deployment
- Credit card fraud detection
- Buy/sell signals
- Risk management
- Example Financial Events:
- New product added
- Risk limit breached
- Order filled
- Fed announcement
- Company news reported
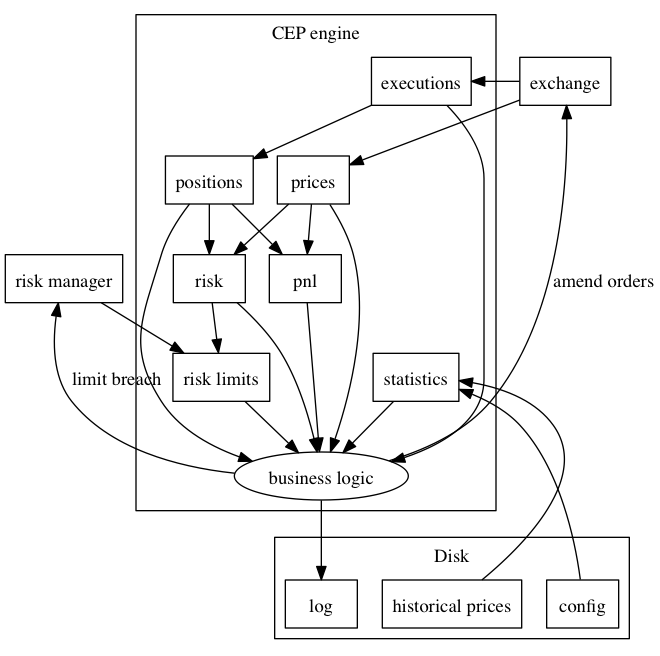
Sample Decision Flow
Why High Performance
- Software cost
- Hardware costs
- Support costs
- Opportunity costs
CEP = KDB+
Where to Focus
- Q is handicapped
- Every operation checks the type of each operand
- Arithmetic operations must check for null and +-infinity
- Types are converted at runtime
- Q is optimized
- Vector operations use cpu specific instruction sets
- Single threaded so no mutex needed
- High level routines are highly optimized
- Maximize the time your code spends executing algorithms in C instead of Q
- Minimize the amount of memory allocated and avoid removing elements from data structures
- Prefer high level data-structures and native operators to atoms and hand-rolled functions
Use Native Left Join
lj:{
$[`s=-2!y;aj[!+!y;x;0!y]; <1>
.Q.ft[{ <2>
$[&/j:(#y:. y)>i?:(!+i:!y)#x; <3>
.Q.fl[x]y i; <4>
+.[+x;(f;j);:; <6>
.+.Q.fl[((f:!+y)#x:.Q.ff[x]y)j] y i j:&j] <5>
]}[;y]]x]}
- check for sorted attribute and call
aj .Q.ftunkeys tables applies function and rekeys- check for case where all keys are found
- just fill data with
.Q.fl .Q.ffadds all new columns with null values- fills only those rows with new data
Lightweight CEP Event
- No key
- Every q-sql update performed unkeys the table, updates the table, then rekeys the table.
- Not sorted
- We can ask for what we want
- No filling
- Nulls are awesome
- Wait until business decision is needed
- Null trade price
- Null bid size vs no bid size
Setup
q)n:10000
q)sym:([]`u#sym:neg[n]?`4)
q)quote:sym!([]bs:n?100;bp:.1*n?100;ap:.1*n?100;as:n?100)
q)trade:sym!([]ts:n?100;tp:.1*n?100)
q)quote
sym | bs bp ap as
----| -------------
jkom| 75 4.8 3.9 23
deco| 51 2.1 7.3 6
knoe| 63 2.4 1.6 19
ppbc| 64 1.6 7.5 5
..
q)r:rand key quote
q)t:enlist r
Left Join
q)t lj quote
sym bs bp ap as
------------------
lgda 85 3.2 9.2 42
q)r lj quote
sym| `lgda
bs | 85
bp | 3.2
ap | 9.2
as | 42
q)\ts do[1000;t lj quote]
25 1232j
q)\ts do[1000;r lj quote]
23 1040j
Faster Left Join
k).q.flj:{x,'y (!+!y)#x} / fast left join
k).q.dlj:{x, y (!+!y)#x} / dict left join
q)\ts do[1000;t lj quote]
25 1232j
q)\ts do[1000;t flj quote]
9 704j
q)\ts do[1000;r lj quote]
23 1040j
q)\ts do[1000;r dlj quote]
9 624j
Native Left Join
q)\ts do[1000;t lj quote]
25 1232j
q)\ts do[1000;t flj quote]
9 704j
q)\ts do[1000;t ,\: quote]
7 704j
q)\ts do[1000;r lj quote]
23 1040j
q)\ts do[1000;r dlj quote]
9 624j
q)\ts do[1000;r , quote]
9 624j
Use Views
- Derived data requires computations
- Three choices:
- Update computation on every tick - performance degrades exactly when we need it
- Recompute every time we need the data - can result in computations even when nothing has changed
- Recompute on a timer - can produce stale results
Views Are The Solution
- Only performs computations when the data has changed AND we need the result of the computation
- Lazy evaluation/caching
- Not memoization
Example
q)micro::update mp:(as;bs) wavg (bp;ap) from quote
q)micro
sym | bs bp ap as mp
----| -----------------------
jkom| 75 4.8 3.9 23 4.644604
deco| 51 2.1 7.3 6 3.448148
knoe| 63 2.4 1.6 19 2.31028
ppbc| 64 1.6 7.5 5 3.030303
ikel| 54 0.2 8.4 12 0.3344262
..
- Quote update only updates quote table
- Recalc only gets called if quote table has changed
- Calculations are vectorized
- Depends on the frequency of read vs write
Use Foreign Keys
CEP events inevitably grow to dozens of fields
The Problem:
- Linear search is slow - unless add
`u# - Fields at end take longest time to find
- Dict keeps re-allocating memory
The Solution:
- Create a view with foreign keys to all reference tables
- Native join with view on CEP event
- Use foreign key lookups (.) instead of
lj - Create functions for calculations with many throw away steps
Example Use of Foreign Keys
q)fkey::1!update sym,q:`quote$sym,t:`trade$sym from sym
q)r:r,fkey
q)t:t,\:fkey
q)select sym,q.as,q.bs,t.ts from t
sym as bs ts
-------------
life 85 80 62
q)select sym,q.as,q.bs,t.ts from r
sym| `life
as | 85
bs | 80
ts | 62
q)select sym,q.as,q.bs,t.ts from t
sym as bs ts
-------------
life 85 80 62
Use Native Column Select
q)1!select sym,bp,ap from quote
sym | bp ap
----| -------
jkom| 4.8 3.9
deco| 2.1 7.3
knoe| 2.4 1.6
ppbc| 1.6 7.5
ikel| 0.2 8.4
..
- Can not
selectwith key intact - We must rekey
Native Column Select
q)`bp`ap#/:quote
sym | bp ap
----| -------
jkom| 4.8 3.9
deco| 2.1 7.3
knoe| 2.4 1.6
ppbc| 1.6 7.5
ikel| 0.2 8.4
..
q)\ts do[1000;1!select sym,bp,ap from quote]
6 1184j
q)\ts do[1000;`bp`ap#/:quote]
3 704j
Summary
Writing Q with the familiar code adds many behind the scenes operations:
upd:{[t]
t:t lj 1!select sym,bs,bp,ap,as from quote;
t:t lj 1!select sym,ts,tp from trade;
t:update mp:(as;bs;ts) wavg (bp;ap;tp) from t;
t}
- Unkeying then rekeying
- ‘friendly’ filling2
- Asking for the obvious (key)
- O(n) field/column lookups
Putting It All Together
nupd:{[t]
t:t,\:fkey;
t:update mp:(q.as;q.bs;t.ts) wavg (q.bp;q.ap;t.tp) from t;
t}
dupd:{[r]
r,:fkey;
r:update mp:(q.as;q.bs;t.ts) wavg (q.bp;q.ap;t.tp) from r;
r}
q)\ts do[1000;upd t]
65 1792j
q)\ts do[1000;nupd t]
21 912j
q)\ts do[1000;dupd r]
17 624j
-
KDB+ 3.0 has redefined
ljto remove filling:lj:{.Q.ft[,\\:[;y]][x]}↩